Short-term update: shared by Fox Business host (w/ Maria Bartiroma) Anthony Scaramucci, and one of the most read on Zero Hedge. Latest article (though pre-Trump video is here).
How poor have the election forecasters been this year? It is a topic that many are discussing given the large number of upsets we've had during the recent Primaries. For example, analyst Nate Silver (who started this campaign season proclaiming that Trump had <2% chance of being nominated) by March 1 instead predicted with 94% probability that Trump would win Alaska (he lost). Silver then predicted on March 8 with >99% probability that Clinton would win Michigan (she lost). And again on May 3, Silver predicted with 90% probability that Clinton would win Indiana (she lost). Notice the pattern? But there is another issue besides being wrong, which is how much model flip-flopping is occurring just up to the date of the elections (a sign of ineptness). The most proximate example is Silver stating this last Sunday that Cruz had a 65% chance to win Indiana; by the next day (Monday, and the eve of the election), with little new data, he "adjusts" that to Trump having a 69% chance to win! Terrible. And this mistrust of forecasters stretches well beyond Indiana, since we'll show below that in 14 of 63 state elections (Democrats and Republicans accounted for separately) so far, likely voters have had this sort of shoddy slip-flopping to contend with. An important question we all must have this year is, given the more narrow polling margins for the general election, the degree to which these forecasters have not been able to make sense of their own models. And with the large amount of flip-flopping anyway, how will we ever believe anyone's single forecast representation of who will win in November? Whenever a forecaster repeatedly (here, here) and guardedly blames "special circumstances" for her or his deteriorating performance, that is further sign that trouble is brewing up and is being masqueraded as "everything is awesome".
First we should note that Clinton's recent loss in Indiana is another horrifying loss of those states where a pollster suggested at least 90% accuracy (see our prequel article titled: The mercurial pollster results and which Columbia University statistician Andrew Gelman claimed was "cogent"). The probability of these many errors being simply due to "bad luck" is down to 3%, so highly unlikely.
Now let's look at the 63 states where Silver has provided a time series of his forecasted winner. We documented each of these states in the map below, separating out those which were/are Democratic races from those that are Republican races. We show the Republican states, in green on the right map below. For 7 of 32 states, Silver completely flipped his opinion on which Republican would win and who would lose that state's primary. We instead color those red. Only in Missouri did we color the state yellow, for a partial flip-flop. Since the initial probability Silver gave to his predicted winner was beyond cut in half (from 14% advantage, to 6%). For Republicans, Silver flip-flops in nearly 1 of 4 states! Any general election poll without flip-flopping could have similar odds for the weaker of the two candidates, and now we cut this forecaster's reliability in half by flip-flopping. That's the key to understanding the difference between "the signal and the noise".

For Democrats, things are about the same too, in the 31 states so far, suggesting that this year's difficulties are not a Trump-only phenomenon. In 4 states (red) we see that Silver completely flip-flopped, and in 3 states (yellow) he at least partially flip-flopped. For Democrats, Silver flip-flopped in nearly 1 of 5 states. Different states too versus those on the Republican party, further suggesting there are serious problems at the core of how Silver and other forecasters are modeling and misleading the public as to their accuracy.
Something else to consider is whether these flip-flops are an excusable pattern where the country shifts its psyche fundamentally, over the course of the campaign season so far. So we plot the states and how they have flip-flopped (0% for none, and 100% for full) throughout each day of the campaign season. We show through larger data markers where we have more state forecasts behind them (such as recently near March's Super Tuesday). We see the erratic level of flip-flopping (standard deviation of nearly 20%), through the uptick in the past month (including Indiana).


 Additionally, with the Poweball lottery now in the top 10 largest in history, our lottery research continues to make headways. Most notably it was shared by a former president of the Royal Statistical Society, Spencer Jacab (WSJ), Sharon Epperson (CNBC) and others, Bloomberg star editor Tom Keene, Chief Data Scientist for Booz Allen, and by BloombergView columnist. Last, Defeated managers in assets globally was shared widely, including consultant Tom Brakke, Zero Hedge, and used at a University of Cambridge talk.
Additionally, with the Poweball lottery now in the top 10 largest in history, our lottery research continues to make headways. Most notably it was shared by a former president of the Royal Statistical Society, Spencer Jacab (WSJ), Sharon Epperson (CNBC) and others, Bloomberg star editor Tom Keene, Chief Data Scientist for Booz Allen, and by BloombergView columnist. Last, Defeated managers in assets globally was shared widely, including consultant Tom Brakke, Zero Hedge, and used at a University of Cambridge talk.
 Last, it is worth seeing these European Central Bank and Mario Draghi's logic-defying conclusions: 2nd GDP gets leaked but not the 1st. CPI but not jobs. Existing homes but not starts.
Last, it is worth seeing these European Central Bank and Mario Draghi's logic-defying conclusions: 2nd GDP gets leaked but not the 1st. CPI but not jobs. Existing homes but not starts.
How poor have the election forecasters been this year? It is a topic that many are discussing given the large number of upsets we've had during the recent Primaries. For example, analyst Nate Silver (who started this campaign season proclaiming that Trump had <2% chance of being nominated) by March 1 instead predicted with 94% probability that Trump would win Alaska (he lost). Silver then predicted on March 8 with >99% probability that Clinton would win Michigan (she lost). And again on May 3, Silver predicted with 90% probability that Clinton would win Indiana (she lost). Notice the pattern? But there is another issue besides being wrong, which is how much model flip-flopping is occurring just up to the date of the elections (a sign of ineptness). The most proximate example is Silver stating this last Sunday that Cruz had a 65% chance to win Indiana; by the next day (Monday, and the eve of the election), with little new data, he "adjusts" that to Trump having a 69% chance to win! Terrible. And this mistrust of forecasters stretches well beyond Indiana, since we'll show below that in 14 of 63 state elections (Democrats and Republicans accounted for separately) so far, likely voters have had this sort of shoddy slip-flopping to contend with. An important question we all must have this year is, given the more narrow polling margins for the general election, the degree to which these forecasters have not been able to make sense of their own models. And with the large amount of flip-flopping anyway, how will we ever believe anyone's single forecast representation of who will win in November? Whenever a forecaster repeatedly (here, here) and guardedly blames "special circumstances" for her or his deteriorating performance, that is further sign that trouble is brewing up and is being masqueraded as "everything is awesome".
First we should note that Clinton's recent loss in Indiana is another horrifying loss of those states where a pollster suggested at least 90% accuracy (see our prequel article titled: The mercurial pollster results and which Columbia University statistician Andrew Gelman claimed was "cogent"). The probability of these many errors being simply due to "bad luck" is down to 3%, so highly unlikely.
Now let's look at the 63 states where Silver has provided a time series of his forecasted winner. We documented each of these states in the map below, separating out those which were/are Democratic races from those that are Republican races. We show the Republican states, in green on the right map below. For 7 of 32 states, Silver completely flipped his opinion on which Republican would win and who would lose that state's primary. We instead color those red. Only in Missouri did we color the state yellow, for a partial flip-flop. Since the initial probability Silver gave to his predicted winner was beyond cut in half (from 14% advantage, to 6%). For Republicans, Silver flip-flops in nearly 1 of 4 states! Any general election poll without flip-flopping could have similar odds for the weaker of the two candidates, and now we cut this forecaster's reliability in half by flip-flopping. That's the key to understanding the difference between "the signal and the noise".

For Democrats, things are about the same too, in the 31 states so far, suggesting that this year's difficulties are not a Trump-only phenomenon. In 4 states (red) we see that Silver completely flip-flopped, and in 3 states (yellow) he at least partially flip-flopped. For Democrats, Silver flip-flopped in nearly 1 of 5 states. Different states too versus those on the Republican party, further suggesting there are serious problems at the core of how Silver and other forecasters are modeling and misleading the public as to their accuracy.
Something else to consider is whether these flip-flops are an excusable pattern where the country shifts its psyche fundamentally, over the course of the campaign season so far. So we plot the states and how they have flip-flopped (0% for none, and 100% for full) throughout each day of the campaign season. We show through larger data markers where we have more state forecasts behind them (such as recently near March's Super Tuesday). We see the erratic level of flip-flopping (standard deviation of nearly 20%), through the uptick in the past month (including Indiana).
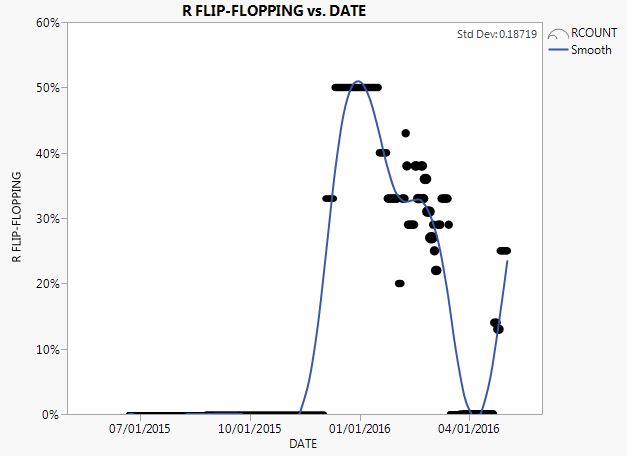
And for Democrats this flip-flopping timeline is only slightly better, but still significantly weak. Note that the smoothed blue line gyrates, from a high at around the start of 2016, to more erratic in the past couple months. Both of these charts suggest that anyone confidently knowing how the size up the Republicans and Democrats -6 months hence on Election Day- is simply being disingenuous about their own models. One would fare better by taking a dice, painting some faces red (for Republican) and others blue (for Democrat); then rolling the dice!

In other news: recent articles have received significant attention. Risks interbred w/ atrocious math has been shared by leading science editors, a 3 time Nobel Peace Prize nominee, and others. Oxford University scientists also took the feedback in stride and it resulted in their findings being recanted with an errata. The head editor of The Atlantic informs us of the same:


No comments:
Post a Comment